안녕하세요~~오~
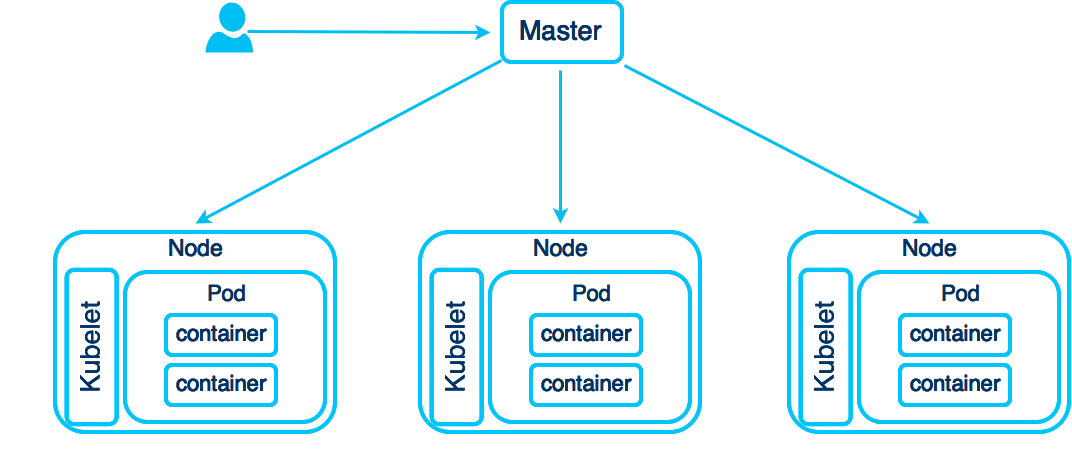
요즘 교육의 목적으로 k8s를 보고 있는데요.
알다시피 k8s를 하다보면 kubectl get 어쩌구 저쩌구 kubectl apply -f 어쩌구 저쩌구 kubectl exec 어쩌구....-_-;;;
내 얼굴 같구만..(답이 없네...)

그래서 앤서블에서 anp(ansible-playbook), ans(ansible) 만든 것처럼, alias를 하려고 좀 알아봤는데..딱 맘에 드는게 없더라고요.
그래서 뭐...맘에 드는 도구가 없다면? 직접 만들어 쓰는게 도리

이렇게 만들었습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | #! /usr/bin/env bash if grep -q sysnet4admin ~/.bashrc; then echo "k8s_rc already installed" exit 0 fi echo -e "\n#custome rc provide @sysnet4admin " >> ~/.bashrc echo "source ~/.k8s_rc " >> ~/.bashrc cat > ~/.k8s_rc <<'EOF' #! /usr/bin/env bash # HoonJo ver0.1 # https://github.com/sysnet4admin/IaC alias kc='kubectl' alias kcg='kubectl get' alias kca='kubectl apply -f' alias kcd='kubectl describe' alias kcc='kubectl create' alias kcs='kubectl scale' alias kce='kubectl export' alias kcl='kubectl logs' alias kcgw='kubectl get $1 -o wide' kcee(){ if [ $# -eq 1 ]; then kubectl exec -it $(kubectl get pods | tail --lines=+2 | awk '{print $1}' | awk NR==$1) -- /bin/bash; else echo "usage: kcee <pod number>" fi } kceq(){ echo -e "" kubectl get pods | tail --lines=+2 | awk '{print NR " " $1}' echo -en "\nPlease select pod in: " read select kubectl exec -it $(kubectl get pods | tail --lines=+2 | awk '{print $1}' | awk NR==$select) -- /bin/bash; } EOF |
다른건 아마 그냥 쓰면 아실텐데..약간 특이한건 kcee, kceq인데요.
컨테이너를 접속하려면 exe -it을 주로 쓰는데요 그리고 -- /bin/bash를 붙여서요. 이건 넘겨받으려다 보니까 alias로 구현하기가 어렵더라고요.
(변: 보통 kubectl을 k로 alias하는데요, 추후에 kubeflow나 다른 kube들 확장을 고려해서 kubectl을 kc로 alias했어요)
그래서 위와 같이 함수로 구현했어요.
사용예제는 요래요래 합니다.
1. 설치 + 설정 다시 로드(su -)
[root@m-k8s ~]# bash <(curl -s https://raw.githubusercontent.com/sysnet4admin/IaC/master/manifests/k8s_rc.sh)
[root@m-k8s ~]# su -
2. 도커 컨테이너 설치
[root@m-k8s ~]# kubectl apply -f https://raw.githubusercontent.com/sysnet4admin/Iac/master/misc/echo-nginx.yaml
3. 설치된 애들 확인
[root@m-k8s ~]# kcg pods
NAME READY STATUS RESTARTS AGE
echo-nginx-5cc884d64c-4kjdh 1/1 Running 0 80s
echo-nginx-5cc884d64c-g2hgb 1/1 Running 0 80s
echo-nginx-5cc884d64c-rkg2x 1/1 Running 0 80s
4. kcee 테스트
[root@m-k8s ~]# kcee 1
root@echo-nginx-5cc884d64c-4kjdh:/#
5. kceq 테스트
[root@m-k8s ~]# kceq
1 echo-nginx-5cc884d64c-4kjdh
2 echo-nginx-5cc884d64c-g2hgb
3 echo-nginx-5cc884d64c-rkg2x
Please select pod in: 3
root@echo-nginx-5cc884d64c-rkg2x:/#
재미나게 쓰세요 :)
빠잉요
+v1 오리댕이님이 소스를 수정해 주셔서 아래와 같이 다시 업데이트 합니다아~
사용방법은 동일합니다.
1. 이건 설정
2. kceq
3. kceq 틀린 네임스페이스
4. kceq kafka
+v1 오리댕이님이 소스를 수정해 주셔서 아래와 같이 다시 업데이트 합니다아~
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 | #! /usr/bin/env bash # kceq revision by 오리댕이 if grep -q sysnet4admin ~/.bashrc; then echo "k8s_rc already installed" exit 0 fi echo -e "\n#custome rc provide @sysnet4admin " >> ~/.bashrc echo "source ~/.k8s_rc " >> ~/.bashrc cat > ~/.k8s_rc <<'EOF' #! /usr/bin/env bash # HoonJo ver0.1 # https://github.com/sysnet4admin/IaC alias kc='kubectl' alias kcg='kubectl get' alias kca='kubectl apply -f' alias kcd='kubectl describe' alias kcc='kubectl create' alias kcs='kubectl scale' alias kce='kubectl export' alias kcl='kubectl logs' alias kcgw='kubectl get $1 -o wide' kcee(){ if [ $# -eq 1 ]; then kubectl exec -it $(kubectl get pods | tail --lines=+2 | awk '{print $1}' | awk NR==$1) -- /bin/bash; else echo "usage: kcee <pod number>" fi } kceq(){ if [ $# -eq 1 ]; then NAMESPACE=$1 exi_chk=($(kubectl get namespaces | tail --lines=+2 | awk '{print $1}')) if [[ ! "${exi_chk[@]}" =~ "$NAMESPACE" ]]; then echo -e "$NAMESPACE isn't a namespace. Try other as below again:\n" kubectl get namespaces exit 1 else kubectl get pods -n $NAMESPACE | tail --lines=+2 | awk '{print NR " " $1}' echo -en "\nPlease select pod in $NAMESPACE: " read select kubectl exec -it -n $NAMESPACE $(kubectl get pods -n $NAMESPACE | tail --lines=+2 | awk '{print $1}' | awk NR==$select) -- /bin/bash; fi elif [ $1 -z ]; then echo "" kubectl get pods | tail --lines=+2 | awk '{print NR " " $1}' echo -en "\nPlease select pod in default: " read select kubectl exec -it $(kubectl get pods | tail --lines=+2 | awk '{print $1}' | awk NR==$select) -- /bin/bash; else echo "" kubectl get namespace echo -e "\nusage: kceq or kceq <namespace>\n" fi } EOF |
사용방법은 동일합니다.
1. 이건 설정
[root@m-k8s ~]# bash <(curl -s https://raw.githubusercontent.com/sysnet4admin/IaC/master/manifests/k8s_rc.sh)
[root@m-k8s ~]# su -
2. kceq
[root@m-k8s ~]# kceq
1 echo-nginx-5cc884d64c-8qc8d
2 echo-nginx-5cc884d64c-9bvxx
3 echo-nginx-5cc884d64c-blg6j
Please select pod in default: 2
root@echo-nginx-5cc884d64c-9bvxx:/#
3. kceq 틀린 네임스페이스
[root@m-k8s ~]# kceq hoonjo
hoonjo isn't a namespace. Try other as below again:
NAME STATUS AGE
default Active 24h
istio-system Active 22h
kafka Active 18h
kube-node-lease Active 24h
kube-public Active 24h
kube-system Active 24h
4. kceq kafka
logout[root@m-k8s ~]# kceq kafka
1 kafka-0
2 pzoo-0
Please select pod in kafka: 1
root@kafka-0:/opt/kafka#
그럼 또 빠잉요
===
흔한 일이 아닌데 업데이트를 또 하네요..
pod 안에 컨테이너가 여러개 있을 경우가 있다고 오리님이 소스를 주셔서 수정합니다.
이제 이거만 봐도 아마 다들 아시겠죠? 고로 설명은 생략 :)
[root@m-k8s ~]# kceq
1 echo-nginx-5cc884d64c-djk4k
2 echo-nginx-5cc884d64c-l8hsj
3 echo-nginx-5cc884d64c-nljnn
4 elder-yak-mariadb-master-0
5 elder-yak-mariadb-slave-0
6 wiggly-fox-redis-master-0
7 wiggly-fox-redis-slave-0
Please select pod in default: 2
root@echo-nginx-5cc884d64c-l8hsj:/# exit
exit
[root@m-k8s ~]# kceq 1
1 isn't a namespace. Try other as below again:
NAME STATUS AGE
default Active 108m
istio-system Active 15m
kafka Active 40m
kube-node-lease Active 108m
kube-public Active 108m
kube-system Active 108m
usage: kceq or kceq <namespace> [-c]
logout
[root@m-k8s ~]# kceq
-bash: kceq: command not found
[root@m-k8s ~]# su -
[root@m-k8s ~]# kceq istio-system
1 grafana-6b65874977-4vs4r
2 istio-citadel-86d9c5dc-877pq
3 istio-egressgateway-7cb7fdff55-qf7t5
4 istio-galley-6ff4cbc457-bnc55
5 istio-ingressgateway-68884574c5-gjkbx
6 istio-pilot-5646cc96d4-66j9x
7 istio-policy-7c76fb7fdb-xnw7j
8 istio-sidecar-injector-5464f6dff-wcfhb
9 istio-telemetry-557d4bf784-sspmw
10 istio-tracing-c66d67cd9-qts9r
11 kiali-8559969566-5zsxg
12 prometheus-66c5887c86-qc6c2
Please select pod in istio-system: 5
root@istio-ingressgateway-68884574c5-gjkbx:/# exit
exit
[root@m-k8s ~]# kceq kafka -c
1 kafka-0
2 pzoo-0
Please select pod in: 2
1 init-config
2 zookeeper
Please select container in: 2
root@pzoo-0:/opt/kafka#
===
흔한 일이 아닌데 업데이트를 또 하네요..
pod 안에 컨테이너가 여러개 있을 경우가 있다고 오리님이 소스를 주셔서 수정합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | NAMESPACE=$1 exi_chk=($(kubectl get namespaces | tail --lines=+2 | awk '{print $1}')) #check to exist namespace but it is not perfect due to /^word$/ is not work if [[ ! "${exi_chk[@]}" =~ "$NAMESPACE" ]]; then echo -e "$NAMESPACE isn't a namespace. Try other as below again:\n" kubectl get namespaces echo -e "\nusage: kceq or kceq <namespace> [-c]\n" exit 1 elif [ $# -eq 1 ]; then kubectl get pods -n $NAMESPACE | tail --lines=+2 | awk '{print NR " " $1}' echo -en "\nPlease select pod in $NAMESPACE: " read select kubectl exec -it -n $NAMESPACE $(kubectl get pods -n $NAMESPACE | tail --lines=+2 | awk '{print $1}' | awk NR==$select) -- /bin/bash; elif [ $# -eq 2 ]; then if [ ! $2 == "-c" ]; then echo -e "only -c option is available" exit 1 fi echo -e "" kubectl get pods -n $NAMESPACE | tail --lines=+2 | awk '{print NR " " $1}' echo -en "\nPlease select pod in $NAMESPACE: " read select POD_SELECT=$select POD=$(kubectl get pods -n $NAMESPACE | tail --lines=+2 | awk '{print $1}' | awk NR==$select) echo -e "" kubectl describe pod -n $NAMESPACE $POD | grep -B 1 "Container ID" | egrep -v "Container|--" | awk -F":" '{print NR $1}' echo -en "\nPlease select container in: " read select CONTAINER=$(kubectl describe pod -n $NAMESPACE $POD | grep -B 1 "Container ID" | egrep -v "Container|--" | awk -F":" '{print $1}' | awk NR==$select) kubectl exec -it -n $NAMESPACE $(kubectl get pods -n $NAMESPACE | tail --lines=+2 | awk '{print $1}' | awk NR==$POD_SELECT) -c $CONTAINER -- /bin/bash; #default pod run elif [ $1 -z ]; then echo "" kubectl get pods | tail --lines=+2 | awk '{print NR " " $1}' echo -en "\nPlease select pod in default: " read select kubectl exec -it $(kubectl get pods | tail --lines=+2 | awk '{print $1}' | awk NR==$select) -- /bin/bash; else echo "" kubectl get namespace echo -e "\nusage: kceq or kceq <namespace> [-c]\n" fi |
이제 이거만 봐도 아마 다들 아시겠죠? 고로 설명은 생략 :)
[root@m-k8s ~]# kceq
1 echo-nginx-5cc884d64c-djk4k
2 echo-nginx-5cc884d64c-l8hsj
3 echo-nginx-5cc884d64c-nljnn
4 elder-yak-mariadb-master-0
5 elder-yak-mariadb-slave-0
6 wiggly-fox-redis-master-0
7 wiggly-fox-redis-slave-0
Please select pod in default: 2
root@echo-nginx-5cc884d64c-l8hsj:/# exit
exit
[root@m-k8s ~]# kceq 1
1 isn't a namespace. Try other as below again:
NAME STATUS AGE
default Active 108m
istio-system Active 15m
kafka Active 40m
kube-node-lease Active 108m
kube-public Active 108m
kube-system Active 108m
usage: kceq or kceq <namespace> [-c]
logout
[root@m-k8s ~]# kceq
-bash: kceq: command not found
[root@m-k8s ~]# su -
[root@m-k8s ~]# kceq istio-system
1 grafana-6b65874977-4vs4r
2 istio-citadel-86d9c5dc-877pq
3 istio-egressgateway-7cb7fdff55-qf7t5
4 istio-galley-6ff4cbc457-bnc55
5 istio-ingressgateway-68884574c5-gjkbx
6 istio-pilot-5646cc96d4-66j9x
7 istio-policy-7c76fb7fdb-xnw7j
8 istio-sidecar-injector-5464f6dff-wcfhb
9 istio-telemetry-557d4bf784-sspmw
10 istio-tracing-c66d67cd9-qts9r
11 kiali-8559969566-5zsxg
12 prometheus-66c5887c86-qc6c2
Please select pod in istio-system: 5
root@istio-ingressgateway-68884574c5-gjkbx:/# exit
exit
[root@m-k8s ~]# kceq kafka -c
1 kafka-0
2 pzoo-0
Please select pod in: 2
1 init-config
2 zookeeper
Please select container in: 2
root@pzoo-0:/opt/kafka#